
OpenAI comes clean about GPT 3.5
Instruction tuning is the future, but RLHF via PPO seems finicky in practice.


GPT-3 has been available since 2020, so why does it feel like the hype is only getting started now? The reason is that OpenAI’s models got much better. They got better thanks to instruction tuning. But not quite in the way we thought.
Early this year, OpenAI announced a new type of model, InstructGPT (paper). The original GPT-3 model was trained on a giant corpus of books and websites. In practice, users don’t usually want to prompt the model with the beginning of a document and get the remainder of the document. They want to ask it to respond to requests. To facilitate this, InstructGPT is trained on instruction prompts, and in particular, human ratings of GPT-3’s completions in response to those instruction prompts. The post introducing InstructGPT emphasized the use of reinforcement learning to train InstructGPT, a method known as RLHF (Reinforcement Learning from Human Feedback). Shortly thereafter, they announced that their new default model, text-davinci-002, would incorporate instruction tuning.
It turned out that text-davinci-002 was in fact much easier to work with, following simple instructions without the need for aggressive prompt engineering. Much of the community assumed that this meant that this new model was built with RLHF. But in the months since, rumors circulated that it actually wasn’t, as baffled LessWrong poster Janus noted:

OpenAI finally clarified the matter this week when they launched text-davinci-003 (doc). We now know that 002 was trained using a simpler method known as FeedMe:

text-davinci-001, text-davinci-002, and davinci-instruct-beta used some of the data that was created in the process of building InstructGPT, but used simpler instruction tuning methods. At long last, text-davinci-003 is the RLHF instruct model trained via PPO.
A (slightly) negative sign for RLHF
Now that we finally have access to the PPO model in the wild, we can ask a crucial question: what is the relative cost-benefit ratio of these methods? We know instruction tuning is highly valuable. Google’s work on Flan demonstrates the value of instruction tuning. Flan-PaLM 520B exceeded Hypermind’s forecasts for the MMLU question-answering benchmark two years early (paper):

Flan can also make small models as powerful as larger models. For example, Flan-T5 with 11B parameters beats the 62B parameter version of PaLM on MMLU. The trick Google used to achieve these results is a relatively simple: Take a pretrained model, and fine tune it on a corpus of “good” prompt completions.
text-davinci-002 was trained using a method OpenAI calls SFT. This is not identical to Flan, but I’m honestly having trouble figuring out exactly what it is. In the paper it’s described thus:

I’m not sure whether “supervised fine tuning” here means just training on a corpus of instructions with loss determined by predicting the next token (which would be very similar to Flan), or if this is actually a form of RL that doesn’t use PPO. If anyone can clarify please let me know!!
RLHF is more complex. A reward model is trained based on labeler judgments, and GPT-3 is then tuned to maximize that reward function using the PPO reinforcement learning algorithm. OpenAI’s diagram is here:
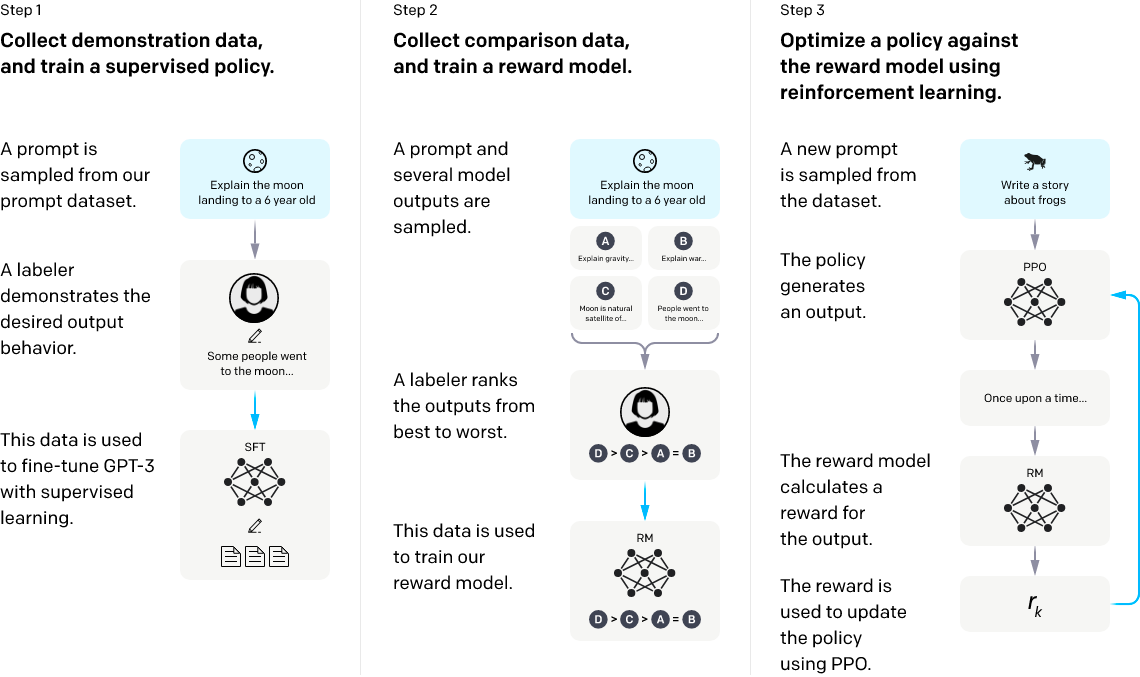
We know from the InstructGPT paper that the PPO method improves alignment with human raters considerably, and so can in principle expect to see significant gains in our own subjective judgments of completions as we shift to the new text-davinci-003 model:

But this still leaves the question: why did it take so long to launch the PPO model after publishing these results? My suspicion is that this approach is hard to work with.
Why this is important
In my previous post, I noted that task-oriented training will be crucial for building action-oriented systems. Just as GPT-3 was not adept at responding to instructions when it was first trained on a large corpus of documents, LLMs are unlikely to be adept at using actions in the most effective possible manner out of the box. They will require task-oriented training.

The question for a developer is, what sort of task-oriented training should I plan on using? Instruction finetuning is straightforward to execute and can produce fantastic results, as the Flan work shows. OpenAI’s work on InstructGPT shows that RLHF with PPO can materially improve on the Flan results.
But it’s a lot trickier. Some have expressed skepticism that this will ever be a common approach. All RL models are tricky to work with and PPO is no exception. Models do strange things, for example defaulting to stereotyped behaviors in a phenomenon known as mode collapse. This may be the reason it took so long for OpenAI to actually ship an RLHF model to the public.
One idle speculation: In the original InstructGPT paper, the RLHF model they tune (labeled PPO here) hallucinates much more than the model trained with the SFT method. So it’s possible that they didn’t want to release until they had solved this problem.

The delayed launch suggests that even OpenAI found executing RLHF via PPO finicky. text-davinci-003 is great to have in our collective toolbox and the results are impressive, but teams fine tuning for their own applications may find it more worthwhile to stick to simpler methods.
CarperAI (a spinoff of Eleuther) is working to build an open source RLHF-tuned model. I’m hoping they can forge a path here that the rest of us can actually follow (post). Or perhaps OpenAI has worked through the problem so well that they’ll be able to provide tools for doing it that are relatively easy to use.
PS: OpenAI is not very… open
This kind of opacity about the meaning of models makes it challenging for researchers to compare their work to OpenAI’s contributions. For example, the Flan paper simply compared their result to the GPT-3 listed in 2020 (`davinci`). This has the advantage of being accurate but the disadvantage of being 2 years out of date, and did not enable a direct comparison to OpenAI’s efforts.

Some papers actually tried to compare to the more recent models, only now to realize these releases didn’t actually make use of RLHF.

All of this is perfectly within OpenAI’s rights, but caveat emptor as you read the literature!
Is FeedMe equivalent to just Step 1 of RLHF or am I misunderstanding?